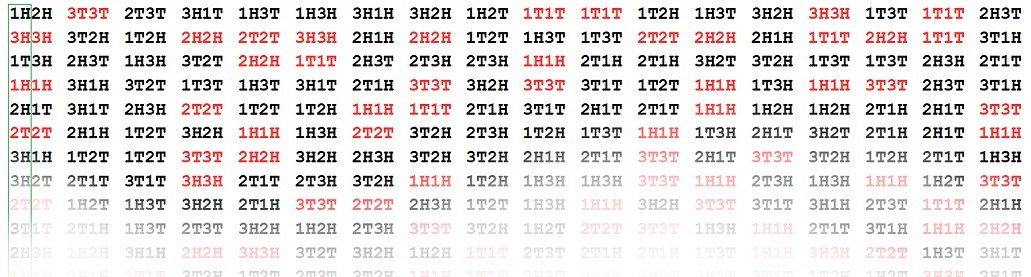
| Words |
Flap 1 |
Flap 2 |
Flap 3 |
| Flap 1 |
100% are the
same (1T1T or 1H1H) |
55% are the same (1T2T or 1H2H) |
61% are the same (1T3T or 1H3H) |
| Flap 2 |
54% are the same (2T1T or 2H1H) |
100% are the
same (2T2T or 2H2H) |
45% are the same (2T3T or 2H3H) |
| Flap 3 |
55% are the same (3T1T or 3H1H) |
49% are the same (3T2T or 3H2H) |
100% are the
same (3T3T or 3H3H) |
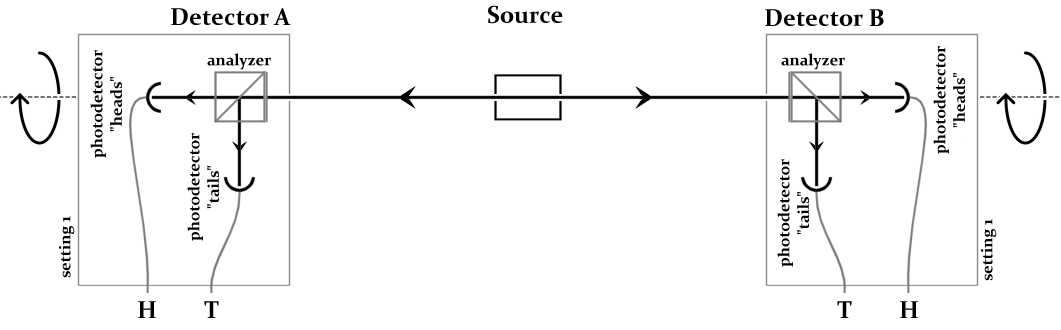
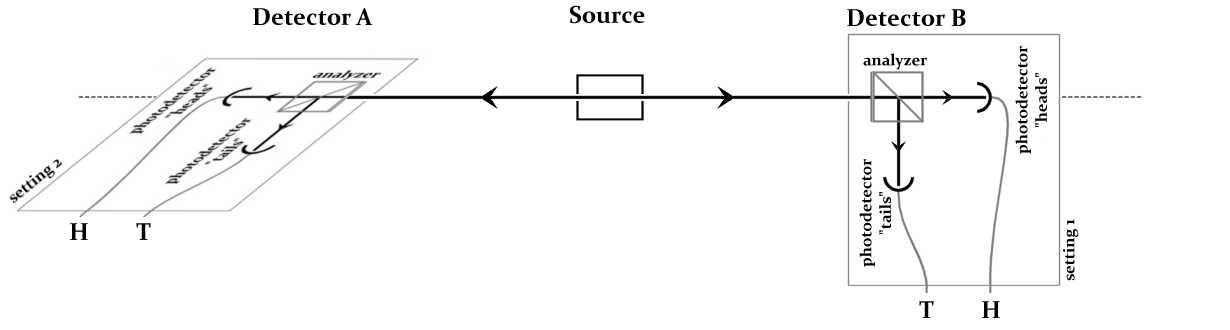
| Outputs |
Setting 1 |
Setting 2 |
Setting 3 |
| Setting 1 |
>99% are
the same |
~25% are the same |
~25% are the same |
| Setting 2 |
~25% are the same | >99% are the same | ~25% are the same |
| Setting 3 |
~25% are the same | ~25 % are the same | >99% are the same |